


끊임없는 도전과 개선을 통해 고객이 추구하는 가치를 더욱 풍요롭게 만들어 드립니다.

Paxata는 Enterprise Self-Service Data Prep 플랫폼입니다.
Paxata 소개
Paxata 는 IT 및 현업 사용자들이 데이터를 취합, 가공하기 위해 수행하는 수작업의 대부분을 줄일 수 있도록 도와주는 Enterprise Self-Service Data Prep 플랫폼입니다.
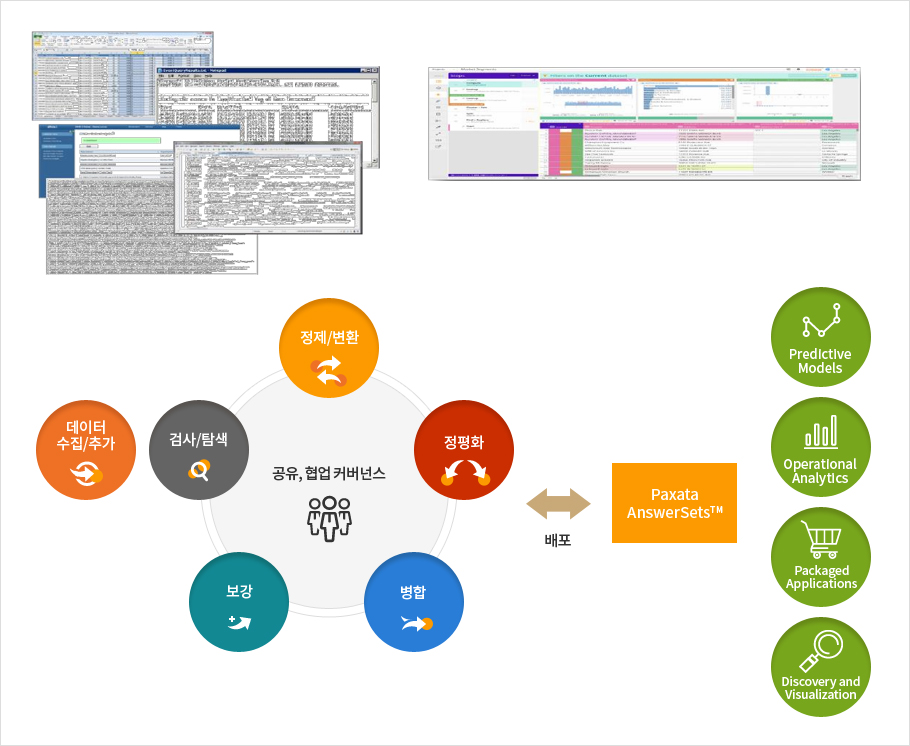
Paxata의 특징 및 기능
- 데이터를 찾고 가공하여 원하는 분석 및 리포트에 소요되는 시간과 비용을 획기적으로 축소 (1-day reporting and agile data discovery)
- 현업 업무를 잘 아는 사용자가 IT 지식없이 데이터를 enrich 하여 인사이트 확보 및 의사결정 지원
- AI 기반 Machine Learning 엔진이 탑재되어 Fussy Join 추천 및 NLP(자연어 처리)를 이용한 데이터 표준화 가능
- Spark 기반 In-Memory 와 Parallel/Distributed Processing 을 이용하여 매우 빠르게 처리
- 데이터 거버넌스 (버전 및 작업 Step 추적, 로깅 등) 강화 및 데이터 리니지 확보
Paxata 플랫폼: Enterprise Self-Service Data Platform
Big Data and AI Platform
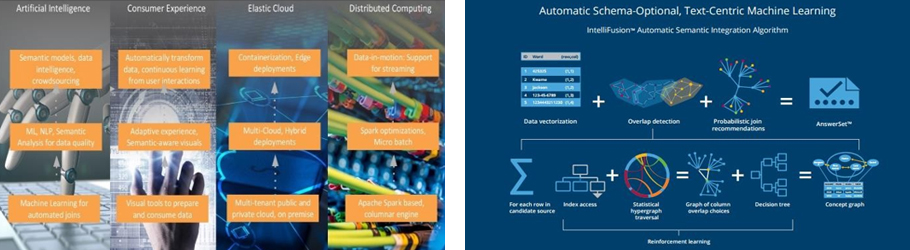
Paxata의 활용
- Agile 데이터 분석 (No need of ETL & Modeling), Ad-hoc 분석은 요청 후 1-Day 지원가능
- Multi-Source 데이터 결합 용이, Semi-structured data 처리, 기존 BI 도구 연계(Clicktoprep)
- 사용자가 직접 데이터 품질 이슈 해결(DQ) 가능 : Dirty & unstandardized values, Missing values, Duplicates, Misspellings & Variations, Blanks & Nulls, Inconsistent formats
- AI로 사회보장관련 내부, 외부 Data 자동결합으로 데이터 기반의 각종 통계, 정책의 신속한 반영 및 NLP(자연어 처리)를 이용한 다양한 데이터의 표준화로 데이터 정합성 확보
- 단기간 교육으로 사용가능하며, 견고한 플렛폼 기반의 사회보장 데이터 자산화 허브
-
 데이터 수집Paxata는 Excel, CSV, JOSN, XML, Avro와 같은 로컬 파일에서 부터 Hadoop 데이터 레이크
데이터 수집Paxata는 Excel, CSV, JOSN, XML, Avro와 같은 로컬 파일에서 부터 Hadoop 데이터 레이크
또는 NoSQL 데이터베이스에 존재하는 반정형화된 데이터, 그리고 SalesForce와 같은 Web
Service 데이터, 관계형 데이터베이스 또는 비즈니스 어플리케이션에 이르기까지 광범위한
데이터 소스들과 함께 작동합니다.
Paxata 라이브러리에 데이터를 추가하기 위해 이용할 수 있는 방법들에 대해 다음 QuickTip
비디오를 시청해 보세요.
-
 검사 및 탐색데이터를 빠르게 이해하고 데이터준비의 필요성을 확인하기 위한 시각적이고 쌍방향적인 데이터 준비와 함께 실시간으로 데이터를 탐색합니다. Paxata는 전체 텍스트 검색, 텍스트, 날짜 밑 순서 필터와 히스토리그램을 제공하며 패턴, 복제, 공백, 오류와 분실된 데이터를 강조해주는 기능을 제공합니다, 실제 사용에 기초하여 대규모의 데이터 세트에 관해 쌍방향적으로 작업하거나 데이터 샘플을 지능적으로 제시합니다.
검사 및 탐색데이터를 빠르게 이해하고 데이터준비의 필요성을 확인하기 위한 시각적이고 쌍방향적인 데이터 준비와 함께 실시간으로 데이터를 탐색합니다. Paxata는 전체 텍스트 검색, 텍스트, 날짜 밑 순서 필터와 히스토리그램을 제공하며 패턴, 복제, 공백, 오류와 분실된 데이터를 강조해주는 기능을 제공합니다, 실제 사용에 기초하여 대규모의 데이터 세트에 관해 쌍방향적으로 작업하거나 데이터 샘플을 지능적으로 제시합니다.
여기의 Paxata Quick Tip에서 확인해보십시오.
-
 정제 및 변환NLP를 사용한 유사값들을 자동으로 표준화하고, 컬럼을 분리 및 연결하며, 중복을 제거합니다. 또한 공백과 무효값, 여백을 빠르게 감지 및 재조정합니다. 이는 어떠한 코딩이나 SQL 또는 스크립트가 요구되지 않습니다. 실시간으로 데이터에 미치는 여향을 관찰하고 언제라도 쌍방향적으로 데이터를 보면서 수정합니다. 이러한 기능들이 얼마나 쉽게 작동하는지를 Paxata Quick Tip를 통해 참고해 보십시오.
정제 및 변환NLP를 사용한 유사값들을 자동으로 표준화하고, 컬럼을 분리 및 연결하며, 중복을 제거합니다. 또한 공백과 무효값, 여백을 빠르게 감지 및 재조정합니다. 이는 어떠한 코딩이나 SQL 또는 스크립트가 요구되지 않습니다. 실시간으로 데이터에 미치는 여향을 관찰하고 언제라도 쌍방향적으로 데이터를 보면서 수정합니다. 이러한 기능들이 얼마나 쉽게 작동하는지를 Paxata Quick Tip를 통해 참고해 보십시오.
-
 정형화단 한번의 클릭으로 데이터를 피벗 또는 디피벗시킬 수 있고 칼럼을 분리시킬수 있으며, 집계를 생성할 수 있습니다. 이는 필요한 분석 실행에 데이터세트를 보다 적합하게 만드는 것을 빠르게 도와줍니다. 이러한 기능의 작동 방법의 예시를 Paxata Quick Tip를 통해 참고해 보십시오.
정형화단 한번의 클릭으로 데이터를 피벗 또는 디피벗시킬 수 있고 칼럼을 분리시킬수 있으며, 집계를 생성할 수 있습니다. 이는 필요한 분석 실행에 데이터세트를 보다 적합하게 만드는 것을 빠르게 도와줍니다. 이러한 기능의 작동 방법의 예시를 Paxata Quick Tip를 통해 참고해 보십시오.
-
 공유 및 거버넌스한번의 클릭을 통해 수행하는 작업을 자동화 할 수 있습니다. 중앙 집중화된 데이터 라이브러리를 이용하여 팀들 간에 있어서 데이터를 공유, 재사용, 협업할 수 있습니다. 비정형 데이터를 정제하고 연결된, 그리고 신뢰 할 수있는 정보로 변환할 때, Paxata의 인증, 승인, 버저닝, 그리고 검사능력으로 인하여 안전하고 확실하며 서비스 공유되는 환경에서 작업할 수 있게 됩니다.
공유 및 거버넌스한번의 클릭을 통해 수행하는 작업을 자동화 할 수 있습니다. 중앙 집중화된 데이터 라이브러리를 이용하여 팀들 간에 있어서 데이터를 공유, 재사용, 협업할 수 있습니다. 비정형 데이터를 정제하고 연결된, 그리고 신뢰 할 수있는 정보로 변환할 때, Paxata의 인증, 승인, 버저닝, 그리고 검사능력으로 인하여 안전하고 확실하며 서비스 공유되는 환경에서 작업할 수 있게 됩니다.
-
 병합대부분의 분석 실행을 위해서는 다중의 데이터세트를 함께 가져오는 것이 필요합니다. 데이터를 통합하기 위해 데이터 작업자는 조인 컬럼과 Key 값을 찾아내야 하므로, 이것은 힘들고 시간이 소요되는 과정일 수 있습니다.
병합대부분의 분석 실행을 위해서는 다중의 데이터세트를 함께 가져오는 것이 필요합니다. 데이터를 통합하기 위해 데이터 작업자는 조인 컬럼과 Key 값을 찾아내야 하므로, 이것은 힘들고 시간이 소요되는 과정일 수 있습니다.
Paxata의 SmartFusion은 IntellifusionTM 머신러닝을 활용하며 데이터세트의 조인이 자동으로 이루어 질 수 있도록 도와줍니다. 이는 두개의 데이터세트를 어떻게 하면 가장 잘 조인할 수 있을 지의 문제를 해결함으로써 이루어 집니다.
한번의 클릭으로 Paxata는 다중의 데이터세트를 단 하나의 AnswerSetsTM 로 조합하고, 그 뒤 다중의 중복된 참조개체들의 중복이 제거된 신뢰할 수 있는 개체로서 통합됩니다. 여기에는 어떠한 스크립트나 SQL, 또는 VLOOKUPS, 피벗 테이블 및 매크로 등과 같은 복잡한 Excel기능이 요구되지 않습니다. 이러한 기능이 어떻게 작동하는지에 관하여 Paxata Quick Tip을 시청해 보십시오.
-
 Paxata와 BI 도구정제되고, 데이터 이력이 있고, 바로 사용 가능합 데이터 세트인 Paxata의 AnswerSetsTM를 당신이 선호하는 BI 도구를 이용하여 쉽게 시각화할 수 있습니다. 이는 Hive 또는 Impala를 통한 직접적 연결 또는 지원하는 파일 형식 안에 데이터를 내보냄으로써 이루어집니다. ClicktoPrep을 이용하여 BI도구와 함께 Paxata의 단일 클릭통합을 이용하여 데이터분석 작업과 데이터 준비 작업을 자유롭게 이동하는 경험을 해보십시오. 이러한 기능이 어떻게 작동하는지에 관하여 Paxata Quick Tip을 시청해 보십시오.
Paxata와 BI 도구정제되고, 데이터 이력이 있고, 바로 사용 가능합 데이터 세트인 Paxata의 AnswerSetsTM를 당신이 선호하는 BI 도구를 이용하여 쉽게 시각화할 수 있습니다. 이는 Hive 또는 Impala를 통한 직접적 연결 또는 지원하는 파일 형식 안에 데이터를 내보냄으로써 이루어집니다. ClicktoPrep을 이용하여 BI도구와 함께 Paxata의 단일 클릭통합을 이용하여 데이터분석 작업과 데이터 준비 작업을 자유롭게 이동하는 경험을 해보십시오. 이러한 기능이 어떻게 작동하는지에 관하여 Paxata Quick Tip을 시청해 보십시오.